TuTh 1.30-2.50
SS 401
Chris Kennedy
Department of Linguistics
Classics 314D
834-1988
Office hours Monday 10.30-12 or by appointment
Eun Hae Park (CA)
Department of Linguistics
401-3456
Office hours Monday 1-2.30 in Linguistics Lounge email
Section
Fridays 2.30-3.20
Cobb 202
Notes on Assignment 3
Part A
The revised Theta Criterion states (in effect) that each type e expression must be the sister of a type [e,t] expression (I'm using square brackets in place of angled brackets here), and vice versa. Assuming the lexicon in the Interpretability handout and the single composition rule of Function Application, this constraint does in fact follow.
The first part follows from the composition system. Since arguments have simple (non-functional) types by definition, and since the only rule for composing the meanings of two constituents is function application, it follows that the sister of an argument denote a function. And in order for the argument to be in its domain, that function is going to have to be type [e, @] (where @ is a variable over arbitrary types), which is the type of a theta assigner (by definition).
The second part follows from the composition system too, but only relative to this lexicon (as we will see in detail below). A theta assigner is type [e, @], so it can combine with an argument (an expression of type e), as the Theta Criterion requires. It could also in principle combine with an expression of type [[e,@], %] (where % is also a variable over types), in which case it would be the argument rather than the function. There are no such expressions in the Interpretability lexicon, however, so this situation does not arise. There are also no other composition rules, which means the only interpretable combination is one in which a theta assigner (type [e,@]) has an argument (type e) as its sister.
One final comment is in order. This argument that the revised Theta Criterion follows from our system (given the Interpretability lexicon) includes an important presupposition: we are relativizing these constraints and operations to cases in which we are deriving propositions (linguistic representations of type t, used to make assertions). The [NP Kim] is `interpretable' in one sense, because it has a denotation (specified in the lexicon). But an occurrence of it without additional structure is not interpretable in the more technical sense assumed here, because our system provides no way to get from this expression to one of type t that can be used as a proposition.
Part B
The result described in Part A would certainly change if we added new lexical entries. For example, if instead of the 'sentence-level' denotation for and given on the Interpretability handout (type [t,[t,t]]), we assumed the 'VP-level' denotation in (i) (type [[e,t], [[e,t],[e,t]]]; this is the version we've been working with in class), the revised Theta Criterion would not follow. (I am using ^ to represent the lambda operator here.)
(i) [[and]] = [^f in D[e,t].[^g in D[e,t].[^x in De.g(x) = 1 and f(x) = 1]]]
This denotation for and renders structures like (ii) interpretable, as shown by the derivation in (iii). (Here I'm leaving out the NP and VP nodes over the subject and the verbs, respectively, and I'm calling the projection of and `ConjP'.)
(ii) [S Kime [ConjP[e,t] smokes[e,t]
[Conj'[[e,t],[e,t]] and[[e,t],[[e,t],[e,t]]] drinks[e,t] ] ] ]
(iii) [[S]] = 1 iff:
- [[ConjP]]([[Kim]]) by Function Application (FA)
- [[Conj']]([[smokes]])([[Kim]]) by FA
- [[and]]([[drinks]])([[smokes]])([[Kim]]) by FA
- [^f in D[e,t].[^g in D[e,t].[^x in De.g(x) = 1 and f(x) = 1]]]([[drinks]])([[smokes]])([[Kim]]) by lexical entry for and
- [^g in D[e,t].[^x in De.g(x) = 1 and [[drinks]](x) = 1]]([[smokes]])([[Kim]]) by lambda simplification
- [^x in De.[[smokes]](x) = 1 and [[drinks]](x) = 1]([[Kim]]) by lambda simplification
- [[smokes]]([[Kim]]) = 1 and [[drinks]]([[Kim]]) = 1 by lambda simplification
- [[smokes]](kim) = 1 and [[drinks]](kim) = 1 by lexical entry of Kim
- [^x in De.x smokes](kim) = 1 and [^x in De.x drinks](kim) = 1 by lexical entries of smokes and drinks
- kim smokes = 1 and [^x in De.x drinks](kim) = 1 by lambda simplification
- kim smokes = 1 and kim drinks = 1 by lambda simplification
(iii) shows both that (ii) is interpretable (in the technical sense) by our system, and that our system gets the truth conditions right (always important)! But (ii) violates the revised Theta Criterion, because both smokes and drinks are theta assigners (expressions of type [e,@]; specifically, both are type [e,t]), yet neither is the sister of an argument (an expression of type e). The set of structures admitted by the revised Theta Criterion is thus a subset of the structures admitted by our system, augmented with the lexical entry for and in (i).
Does this mean that the Theta Criterion is not a principle of grammar after all? Not necessarily; it just shows that the Theta Criterion is inconsistent with particular assumptions about the lexicon and about the syntax --- in this case, the assumption that (i) is the meaning of and and that representations like (ii) are well-formed)
Part C
There are a number of restrictions on Interpretability that our system imposes that are not imposed by the Theta Criterion --- cases where the Theta Criterion alone is not enough to explain semantic ill-formedness. The most obvious involves cases is type mismatch. The Theta Criterion actually handles many of these, since it is in effect a constraint barring combination of type e and [e,@] things with anything but each other. So while our system would rule out [Kim drinks smokes] purely as a type mismatch (there's no way to combine [e,t] drinks and [e,t] smokes), this is also ruled out by the Theta Criterion. However, it says nothing about cases of mismatch between expressions that are neither type e nor type [e,@], whereas our system predicts in general that in order for two constituents to combine, it must be the case that one is a functor and the other is an argument in the functor's domain.
Another restriction on interpretability derived by our system has to do with 'saturation', which is (in essence) the requirement that functional expressions 'discharge' (or saturate) their arguments, so that at the end of the derivation we end up with something of type t. Again, the Theta Criterion can be viewed as a constraint requiring saturation, but only for expressions of type [e,@]: it says nothing about expressions of type [%,@], where % is not e. This means that it says nothing about an example like [[Fred sleeps]t and[t,[t,t]]][t,t]. This expression is unsaturated (it needs to combine with another expression of type t), but since it's not type [e,@], the Theta Criterion doesn't come into effect.
Of course, the Theta Criterion could be augmented with a constraint that says 'make sure that sentences are type t', which would force saturation in non-theta/argument contexts. Then it would look just like our system, without expressing the broader generalization that our system captures: functional types must be saturated!
Part D
Strictly speaking, neither of (4a-b) are interpretable by our system, though the fact that they have a different empirical status (4a) is anomalous while (4b) is garbage) indicates that we need to acknowledge different kinds of uninterpretability. Let's consider (4b) first, because it's the easy case: we don't even have to look at meanings to deal with this example; it's enough to look at the semantic types of the constituents:
(iv) 
We have a type mismatch at the root node here: one daughter is type t, the other is type [e,t], and there is no composition rule that can handle this combination, so the computation breaks down.
(4a) is a bit more complicated. Here, all the types work out, as shown in (v).
(v) 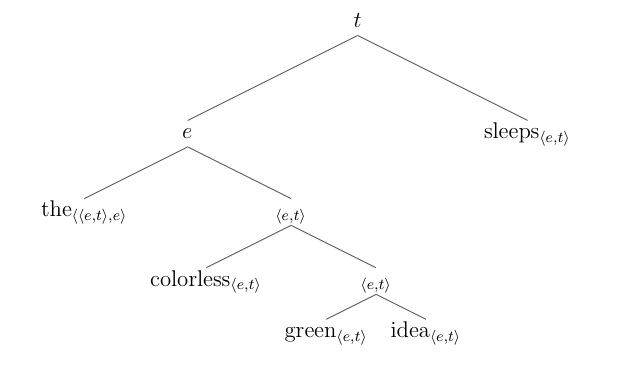
The problem has to do with the computation of the meaning of the subject the colorless green ideas. Assuming the rule of Predicate Modification (PM) the denotation of the in Heim and Kratzer, as well as the meanings for the adjectives and nouns given on the handout, the derivation seems like it ought to work as in (vi). (vi) [[the colorless green ideas]] =
- [[the]]([[ colorless green ideas]]) by FA
- [[the]]([^x in De.[[colorless]](x) = 1 and [[green ideas]](x) = 1]) by PM
- [[the]]([^x in De.[[colorless]](x) = 1 and [^y in De.[[green]](y) = 1 and [[ideas]](y) = 1](x) = 1]) by PM
- [[the]]([^x in De.[[colorless]](x) = 1 and [[green]](x) = 1 and [[ideas]](x) = 1]) by lambda simpification
- [[the]]([^x in De.[^z in De.z is colorless](x) = 1 and [^z in De.z is green](x) = 1 and [^z in De.z is an idea](x) = 1]) by lexical entries of colorless, green and idea
- [[the]]([^x in De.x is colorless = 1 and x is green = 1 and x is an idea = 1]) by lambda simplification
- [^f: f is in D[[e,t],e] and there is a unique x such that f(x) = 1.the y such that f(y) = 1]([^x in De.x is colorless = 1 and x is green = 1 and x is an idea = 1]) by lexical entry of the
But here is where we run into a problem. The function that we are trying to provide as an argument to [[the]] is of the right type ([e,t]), but the domain of [[the]] is not merely delimited by semantic type, as in all of the other cases we have considered so far. It also requires its argument to be a function such that there is a unique object that it applies to. In the case of the function that we are providing as argument --- the function from individuals to truth values that is true of an object x just in case x is colorless and x is green and x is an idea --- there is no such object. But that means that this function is not in the domain of [[the]], and that composition should break down.
It both examples, we fail to derive truth conditions for the sentence. This is good, because both examples are judged to be unacceptable. On the other hand, we still want to explain their different status: anomalous vs. garbage. At one level, it looks as though our system fails to distinguish the examples: both are uninterpretable. At another level, though, our system does distinguish them, because they're uninterpretable for different reasons: (4a) involves a failure of composition due to non-satisfaction of a domain restriction, but it is type-wise OK; (4b) involves a type mismatch. Evidently type mismatches result in stronger judgments of unacceptability, and intuitively this seems right. The pieces are put together correctly in (4a); the reason things fail is because of incompatibility based on (arbitrary) lexical conflicts. In (4b), on the other hand, the pieces aren't even put together correctly. Whether this difference between type mismatch and domain failure is a 'discovery' or a 'problem' for our system is a question that I will leave it to you to answer for yourselves....
Part E
In Part B, we showed that if and has a type [[e,t], [[e,t],[e,t]]] denotation that conjoins (type [e,t]) VPs, then the (revised) Theta Criterion must not be a grammatical constraint: it would incorrectly rule out sentences like (ii), which are of course perfectly interpretable. But it is possible that (ii) is not an actual sentence of English. Instead, it could be the case that sentences with the surface form in (ii) always have the form in (vii) at the level of representation that interfaces with the semantics, which would satisfy the Theta Criterion:
(vii) [ConjP [Kim smokes] [Conj' and [Kim drinks]]]
If empirical research on English syntax leads us to the conclusion that surface strings of the form Kim smokes and drinks must have the structure in (vii) rather than the structure in (ii) (at the relevant level of representation), and if the same could be shown for similar cases, this would in fact provide extremely powerful evidence that the Theta Criterion is a principle of grammar. The argument is precisely that our semantics is set up so that we don't need to assume (vii) to handle such surface strings: we showed above in (iii) that treating and as a VP-conjunct with a type [[e,t], [[e,t],[e,t]]] 'does the right thing', so there is no semantic reason for a more abstract representation like (vii). That means that if we discover that (vii) is the right representation (based on strong and compelling independent arguments, of course), we have to conclude that it is that way for non-semantic reasons! The Theta Criterion could be one such reason. There could of course be other reasons, and there are lots of other predictions that the Theta Criterion makes (about abstract representations) that we would need to test, but you should see how the reasoning works.
The central point here is that it is not really sufficient to say 'our semantics can get things right, so we're done' if our goal is to fully understand that part of linguistic competence that governs the mapping between form and meaning. Methodologically, this might be a reasonable position if our interests are elsewhere, but if we really want to know how this part of language works, we need to look deeper. If we find evidence that the syntax is actually more complex or abstract than the semantics requires, then we need to ask why that is.